

云计算课设
这个课设是一个基于MapReduce的倒排索引系统,核心是Hadoop+docker+k8s
整体架构
前端 vue+nodejs
后端 nodejs+express+redis+sqlite3
部署方法 dockerfile+k8s
数据处理方法 Hadoop
课设灵感
自己blog的搜索功能很弱,采用的是js插件的全局遍历搜索,就在网上查了一下优化方法,顺便知道了倒排索引这种方法,结合云计算课堂的docker和Hadoop知识,便有了这个课设
倒排索引介绍
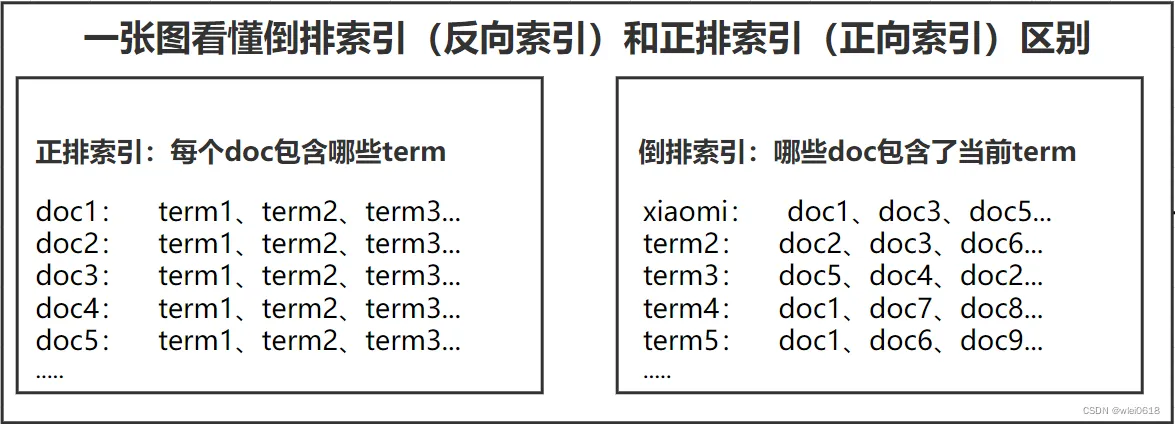
什么是正排索引
可以简单的理解为通过文档找词
文档--> 单词1 ,单词2
单词1 出现的次数 单词出现的位置; 单词2 单词2出现的位置 ...正排索引的优势在于可以快速的查找某个文档里包含哪些词项。同理,正排不适用于查找包含某个词项的文档有哪些。
什么是倒排索引
倒排索引(Inverted Index)是一种常用的文本索引数据结构,用于加快文本搜索和信息检索的速度。它是一种反转(Inverted)的索引结构,将文档中的每个单词映射到包含该单词的文档列表。
通常,倒排索引由两个主要组成部分构成:词项表(Term Dictionary)和倒排列表(Inverted List)。
词项表(Term Dictionary):词项表是一个词项到倒排列表的映射,它记录了所有不重复的单词(或词项)以及它们对应的倒排列表的位置信息。
倒排列表(Inverted List):倒排列表包含了一个单词在文档集合中的出现位置。对于每个单词,倒排列表记录了包含该单词的文档的标识符(例如文档ID)以及该单词在文档中的位置信息(例如单词出现的位置或出现的频率)。
用一个图直观展示两者的区别
前端设计
文件结构
│ .dockerignore│ Dockerfile│ index.html│ package-lock.json│ package.json│ results.html│ server.js│ vite.config.js│├─public│ favicon-16x16.png│ icon_search.svg│ leetcode.png│ title.ttf│└─src └─assets base.css main.css文件介绍
.html文件就是用户搜索/显示题目的页面
public存的图片
src存的样式(ai完成的,自己真的不会写)
dokcerfile和.dockerignore生成docker用
server.js本地启动项目并且用于后续k8s部署时同步环境
package.json用来配置项目依赖,package-lock.json自动生成
交互设计
前后端通过POST互通,经过解析后显示
后端设计
文件结构
├── data/ #数据存放├── src/│ ├── config/ # 配置文件│ ├── controllers/ # 控制器│ ├── models/ # 数据模型│ ├── routes/ # 路由│ ├── services/ # 业务逻辑│ └── utils/ # 工具函数├── Dockerfile # Docker 配置├── package.json # 项目配置└── README.md # 项目说明数据获取
拿的力扣的数据,他们的api用的graphql,本来想用牛客的,结果76跟我说牛客没有这种接口,期末时间紧,也懒得爬了xd
拉数据非常简单,比如
https://leetcode.com/graphql?query=query{ userContestRanking(username: "YOUR_USERNAME") { attendedContestsCount rating globalRanking totalParticipants topPercentage } userContestRankingHistory(username: "YOUR_USERNAME") { attended trendDirection problemsSolved totalProblems finishTimeInSeconds rating ranking contest { title startTime } }}在浏览器里面搜这个,就可以得到一堆数据了
存到数据里面并把url删除,存于data/input.txt里面,类似1 Two Sum Easy array hash-table,准备进行mapreduce的分词
Hadoop处理
- 首先把数据ftp传上去,然后在hdfs里面搞个文件夹,并且数据扔进去
hdfs dfs -mkdir /input hdfs dfs -put ~/input.txt /input/
- 使用mapreduce进行分词
根据Hadoop streaming 的规则,只要我们使用标准的输入输出,什么语言都行,直接nodejs启动了,mapper.js起到这个作用。
在map阶段,我们按行读取内容,并将处理后的内容分为docId 和单词,并使用标准输入输出进行输出方便后续reduce处理,所以就有了reduce.js。
- 生成并且拉出数据
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-3.3.6.jar -D mapreduce.job.maps=4 -D mapreduce.job.reduces=4 -files mapper.js,reducer.js -mapper “node mapper.js” -reducer “node reducer.js” -input /input/input.txt -output /output
hdfs dfs -get /output ~/hadoop_output
- 存入redis
具体来说,我们读取处理好的单词与文章的映射,并根据单词在某个文章中出现的次数对其进行排序,如
ZSM (46,1),(589,1),(32,1),(42,2),(22,1)变成ZSM (42,2),(46,1),(589,1),(32,1),(22,1)
docker部署
前端
# 使用基础的 Node.js 镜像作为基础FROM node:18
# 设置工作目录WORKDIR /usr/src/app
# 将 package.json 和 package-lock.json 复制到工作目录COPY package*.json ./
# 安装依赖RUN npm install
# 复制项目文件到工作目录COPY . .
# 暴露容器的端口(根据你的项目配置)EXPOSE 5173
# 运行前端应用CMD ["node", "server.js"]全部文件拉进去,运行进行了,一定要在里面去npm install,要不然会有环境问题,比如arm和x86的包不兼容
后端
这里我把sqlite3也包进去了,反正比较轻量
FROM node:18-alpine
# 安装构建 better-sqlite3 所需的依赖RUN apk add --no-cache python3 make g++ sqlite-dev
WORKDIR /app
COPY package*.json ./
RUN npm install
COPY . .
EXPOSE 9999
CMD ["npm", "start"]k8s部署
redis部署
首先要理解,每个pod都是和主机环境直接隔离的,如果我想用主机docker上面部署的redis是可以的,但是需要的url就是http://ip:port,是固定的,那你换个网本地调试是不是炸了,所以拿一个port部署redis是很有必要的
apiVersion: apps/v1kind: Deploymentmetadata: name: redisspec: replicas: 1 selector: matchLabels: app: redis template: metadata: labels: app: redis spec: containers: - name: redis image: redis:7.2 ports: - containerPort: 6379---apiVersion: v1kind: Servicemetadata: name: redis-servicespec: selector: app: redis ports: - protocol: TCP port: 6379 targetPort: 6379前端部署
这里我采用docker+k8s,可以看k8s的那个文章,讲了一点点原理,所以本地docker搭建的时候是docker build -t yunjisuanfront:latest .
apiVersion: apps/v1kind: Deploymentmetadata: name: yunjisuan-frontendspec: replicas: 1 selector: matchLabels: app: yunjisuan-frontend template: metadata: labels: app: yunjisuan-frontend spec: containers: - name: yunjisuan-frontend image: yunjisuanfront:latest imagePullPolicy: Never # 使用本地镜像 ports: - containerPort: 5173 # 根据你的前端实际端口调整 env: - name: BACKEND_URL value: "http://yunjisuan-backend-service:9999"---apiVersion: v1kind: Servicemetadata: name: yunjisuan-frontend-servicespec: selector: app: yunjisuan-frontend ports: - port: 5173 targetPort: 5173 type: LoadBalancer # 负载均衡后端部署
apiVersion: apps/v1kind: Deploymentmetadata: name: yunjisuan-backendspec: replicas: 1 selector: matchLabels: app: yunjisuan-backend template: metadata: labels: app: yunjisuan-backend spec: containers: - name: yunjisuan-backend image: yunjisuan-backend:latest imagePullPolicy: Never # 使用本地镜像 ports: - containerPort: 9999 env: - name: DB_PATH value: "/app/data/questions.db" - name: REDIS_HOST value: "redis-service" - name: REDIS_PORT value: "6379" - name: NODE_ENV value: "production" volumeMounts: - name: data-volume mountPath: /app/data volumes: - name: data-volume persistentVolumeClaim: claimName: yunjisuan-data-pvc---apiVersion: v1kind: Servicemetadata: name: yunjisuan-backend-servicespec: selector: app: yunjisuan-backend ports: - port: 9999 targetPort: 9999 type: ClusterIP注意要去吃到数据库和redis的路径/端口,然后再挂个持久化
apiVersion: v1kind: PersistentVolumeClaimmetadata: name: yunjisuan-data-pvcspec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi关于自动化
以上方法虽然用的是last版本,但是有bug的话你就要删掉重建,很麻烦,如何自动推送启用last版本的docker镜像呢???
方法一
利用自动化sh脚本
#!/bin/bashPREVIOUS_DIGEST=""while true; do DIGEST=$(docker image inspect yunjisuanfront:latest --format='{{index .Id}}') if [[ "$DIGEST" != "$PREVIOUS_DIGEST" ]]; then echo "镜像已更新,重启 Deployment..." kubectl rollout restart deployment yunjisuan-frontend PREVIOUS_DIGEST="$DIGEST" fi sleep 10done方法二 使用本地 registry + 镜像 tag 唯一化
每次你 build 镜像时,给它一个唯一 tag(比如使用时间戳、Git 提交哈希),然后更新 Deployment 镜像地址。这样 Kubernetes 会认为镜像变了,从而重建 Pod。
- 本地搭建 Docker Registry
docker run -d -p 5000:5000 —name registry —restart=always registry:2
- 构建并推送带唯一 tag 的镜像
TIMESTAMP=TIMESTAMP . docker push localhost:5000/yunjisuanfront:$TIMESTAMP
- 更新 Deployment 的镜像地址
image: localhost:5000/yunjisuanfront:{{TIMESTAMP}} imagePullPolicy: Always
- 可以使用脚本/CI 工具(如 GitHub Actions)自动完成 build → push → update YAML → apply。
比如
#!/bin/bashset -e
# 1. 生成唯一 tagTAG=$(date +%s)
# 2. 构建镜像docker build -t localhost:5000/yunjisuanfront:$TAG .
# 3. 推送到本地 registrydocker push localhost:5000/yunjisuanfront:$TAG
# 4. 渲染模板envsubst < deploy/frontend.yaml.template > deploy/frontend.yaml
# 5. 应用到 K8skubectl apply -f deploy/frontend.yaml
echo "✅ 镜像 yunjisuanfront:$TAG 已部署到 Kubernetes"鸽子时间
如果有时间,可能会研究持久化抓取数据->Hadoop自动化处理->推送数据库->重建镜像->pod重启,但是比较复杂,而且吃性能,后面再说吧。
咕咕咕
本地小bug(6.12更新)
在本地部署成功之后,需要把后端port转发到本地,原因是,Pod 和 Service 默认是内网通信的,如果前端vue要访问后端api,我必须要走本地这里
kubectl port-forward service/yunjisuan-backend-service 9999:9999 &
云上问题(6.13更新)
dokcer
此docker指的是k8s部署的时候用的docker,本地没有这个问题,可能是orb的功劳?
在docker build -t frontend:latest .后,你拥有了本地镜像,这个时候你也许会运行kubectl apply -f **.yaml,然后kubectl get pod,然后就发现会镜像错误,原因是k8s和docker用的虽然都是containerd,但是不能直接利用!
你需要
docker save frontend:latest -o frontend.tardocker load -i frontend.tarctr -n k8s.io images import frontend.tar //推送到containerd这样才可以使用本地的
部署问题
部署其实在网上有很多教程,为什么我还是配置了一晚上呢?
第一开始并没有详细的看教程,直接apt启动加上个人想象力了,发现环境炸了的时候已经救不回来了,所以后面带着docker整个卸载重装了
最后选择了k3s,更加轻量化,也更好配置(2c2g的服务器搞这种东西真有点难)。
但是问题依旧很多,比如k3s的镜像问题,DNS转发都转发不了的,我选择了全部pull到本地,然后打包成tar传上去,虽然很慢,但是很稳。 为什么不换源呢?我是真的没有找到可以用的,不知道为什么,我可以用的docker源拉到k3s里面都烂了,下次可以试试搞个镜像站吧。
Some information may be outdated